

Translating from one language to another is hard, and creating a system that does it automatically is a major challenge, partly because there’s just so many words, phrases, and rules to deal with. Fortunately, neural networks eat big, complicated data sets for breakfast. Google has been working on a machine learning translation technique for years, and today is its official debut.
The Google Neural Machine Translation system, deployed today for Chinese-English queries, is a step up in complexity from existing methods. Here’s how things have evolved in a nutshell.
Word by word and phrase by phrase
A very simple technique for translating — one a kid or simple computer could do — would be to simply look up each word encountered and switch it with the equivalent word in another language. Of course, the nuances of speech and often the meaning of an utterance can be lost, but this rudimentary word-by-word system can still impart the gist at minimal fuss.
Since language is naturally phrase-based, the logical next move is to learn as many of those phrases and semi-formal rules, applying those as well. But it requires a lot of data (not just a German-English dictionary) and serious statistical chops to know the difference between, for example, “run a mile,” “run a test,” and “run a store.” Computers are good at that, so once they took over, phrase-based translation became the norm.
More complexity lurks still in the rest of the sentence, of course, but it’s another jump in complexity, subtlety, and the computational power necessary to parse it. Ingesting complex rulesets and making a predictive model is a specialty of neural networks, and researchers have been looking into this method, but Google has beaten the others to the punch.
GNMT is the latest and by far the most effective to successfully achieve leverage machine learning in translation. It looks at the sentence as a whole, while keeping in mind, so to speak, the smaller pieces like words and phrases.
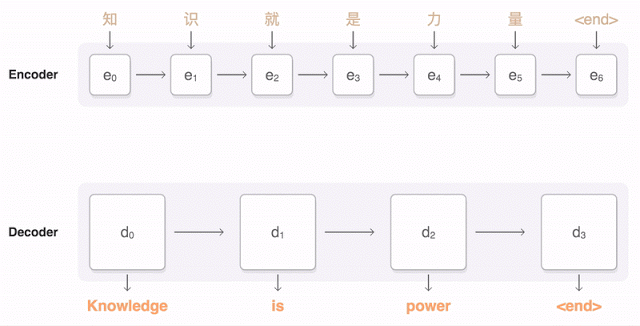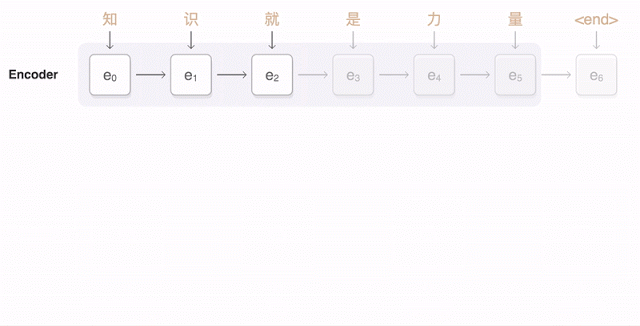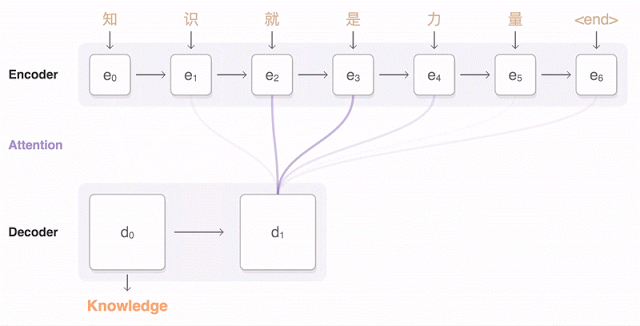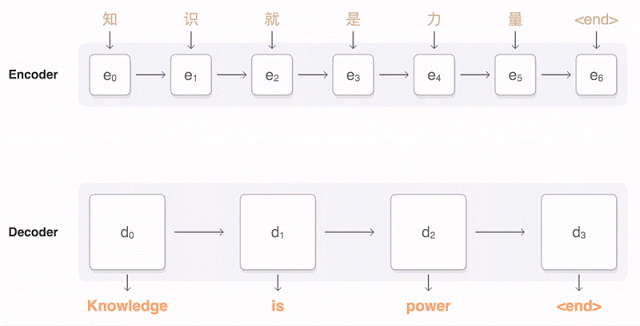
Google’s animation shows how the parts of a Chinese sentence are detected and their relevance to the words to be translated weighed (the blue lines).
It’s much like the way we look at an image as a whole while being aware of individual pieces — and that’s not a coincidence. Neural networks have been trained to identify images and objects in ways imitative of human perception, and there’s more than a passing resemblance between finding the gestalt of an image and that of a sentence.
Interestingly, there’s little in there actually specific to language: the system doesn’t know the difference between the future perfect and future continuous, and it doesn’t break up words based on their etymologies. It’s all math and stats, no humanity. Reducing translation to a mechanical task is admirable but in a way chilling — though admittedly, in this case, little but a mechanical translation is called for, and artifice and interpretation are superfluous.
Advancing the art by removing the art
The paper describing GNMT points out several advances — rather technical ones — that reduce the computational overhead required for processing language this way and avoid its pitfalls.
For example, the system tends to choke on rare words, since their rarity makes them difficult to recognize and associate with other words. GNMT gets around this by breaking uncommon words into smaller pieces that it treats as individual words and learns the associations for.
Actual computing time is reduced by limiting the precision of the math involved and using Google’s Tensor Processing Units, custom hardware designed with neural network training in mind.
The input and output systems are very different, but still exchange information where they interface, allowing them to be trained together and form a more unified in-out process. That’s about as specific as I can get on that one; the details are in the paper if you think you can handle them.
The resulting system is highly accurate, beating phrase-based translators and approaching human levels of quality. You know it has to be good when Google just deploys it to its public website and app for a difficult process like Chinese to English.
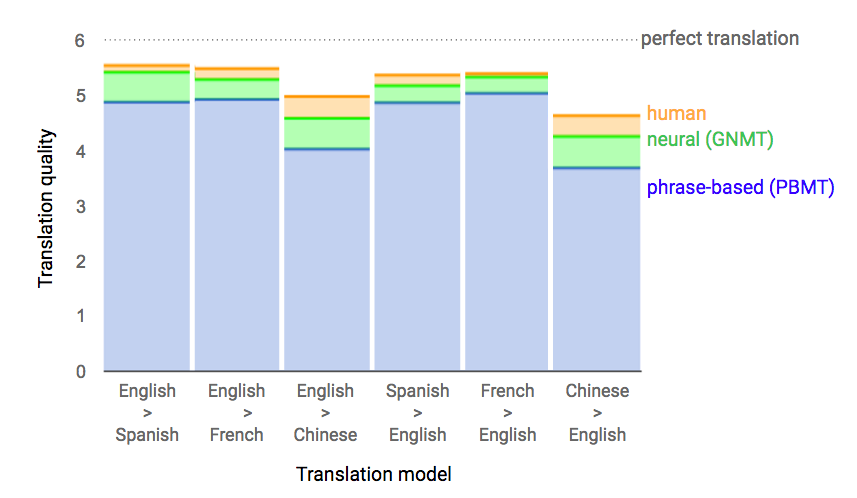
Spanish and French also tested well, and you can expect GNMT to expand in that direction over the coming months.
Black box
One of the downsides is that, as with so many predictive models produced by machine learning, we don’t really know how it works.
“GNMT is like other neural net models – a large set of parameters that go through training, difficult to probe,” Google’s Charina Choi told TechCrunch.
It’s not that they have no idea whatsoever, but the many moving parts of phrase-based translators are designed by people, and when a piece goes wrong or becomes outdated, it can be swapped out. Because neural networks essentially design themselves through millions of iterations, if something goes wrong, we can’t reach in and replace a part. Training a new system isn’t trivial, though it can be done quickly (and likely will be done regularly as improvements are conceived of).
Google is betting big on machine learning, and this translation tool, now live for web and mobile queries, is perhaps the company’s most public demonstration yet. Neural networks may be complex, mysterious, and little creepy, but it’s hard to argue with their effectiveness.
